L'accès à des données de haute qualité est l'un des défis majeurs du développement des grands modèles de langage. Dans sa note stratégique, Thomas Spitz, co-fondateur d'AI Partners, explore les enjeux et les opportunités liés à la construction d'un marché structuré de données d'entraînement.
Créer un marché de données d'entraînement : transparence et propriété intellectuelle dans l'IA
Les grands fournisseurs d'IA comme OpenAI entraînent leurs modèles sur des milliards de pages web collectées sans le consentement des créateurs de contenu. À mesure que les préoccupations éthiques et juridiques grandissent, une marketplace dédiée aux données d'entraînement émerge comme la solution pour garantir transparence, rémunération équitable et respect de la propriété intellectuelle.
Comment les fournisseurs de données alimentent les LLM
Les fournisseurs d'IA s'appuient sur des corpus de données massifs. Deux sources dominent :
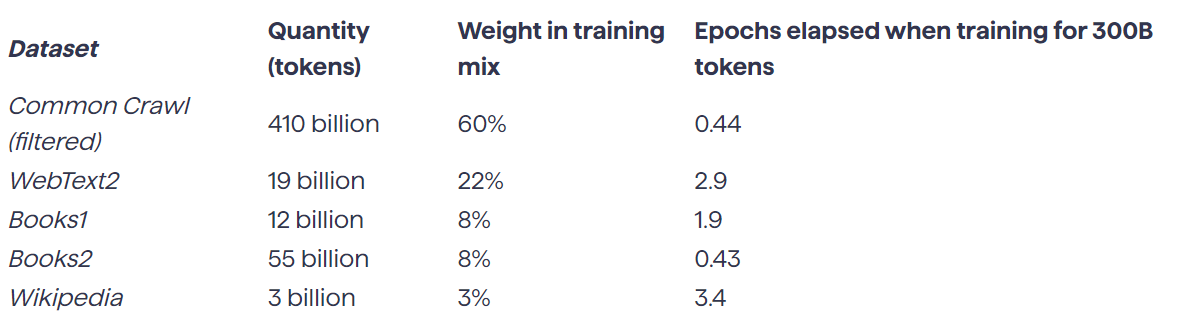
Common Crawl : près de 25 milliards de pages web archivées depuis 2007
The Pile : 22 jeux de données combinés totalisant environ 885 gigaoctets
Ces vastes réservoirs sont souvent compilés sans le consentement explicite des auteurs originaux, soulevant de sérieux défis éthiques et juridiques.
Implications éthiques et juridiques de l'utilisation des données
Les producteurs de contenu, notamment les médias, blogs, éditeurs et l'industrie audiovisuelle, voient leur travail utilisé sans aucune compensation.
Ce qui était autrefois moins controversé lorsque géré par des organisations à but non lucratif comme Common Crawl devient une préoccupation majeure lorsque les mêmes données alimentent des produits commerciaux construits par des géants comme Google, Microsoft et OpenAI.
La frustration des créateurs de contenu est compréhensible. OpenAI, valorisée à plusieurs milliards de dollars, tire une grande partie de sa valeur des données d'entraînement sans jamais rémunérer les personnes qui les ont créées.
Défis et opportunités pour les créateurs de contenu
Une résistance croissante se structure parmi les titulaires de droits sur les données :
Selon Originality.AI, environ 20% des 1 000 sites web les plus visités bloquent activement les crawlers IA
Dans une étude de Homepage.com, 54,3% des éditeurs de sites web ont demandé à OpenAI, Google AI ou Common Crawl de cesser de crawler leur contenu
Dans le même temps, des accords commerciaux marquants confirment qu'un modèle différent est possible. Reddit aurait vendu ses données à OpenAI pour plus de 60 millions d'euros, et le partenariat entre Le Monde et OpenAI prouve que la monétisation explicite des données est réalisable.
Vers une collaboration plus durable
Ces exemples signalent un changement de paradigme : une reconnaissance croissante de la valeur intrinsèque des données, et une évolution vers une collaboration structurée entre créateurs de contenu et développeurs d'IA.
La monétisation explicite n'est plus l'exception. Elle devient la norme attendue.
Comment garantir transparence et propriété intellectuelle dans les données d'entraînement ?
Le besoin d'une Training Data Marketplace est évident. Une telle plateforme fournirait un cadre transparent et responsable pour la gestion des données, garantissant :
Une rémunération équitable pour les créateurs de contenu
La conformité avec les standards éthiques et juridiques
Des modèles d'IA plus riches et diversifiés, entraînés sur des données actuelles et variées
Cette plateforme servirait d'intermédiaire équitable entre les créateurs de contenu et les entreprises d'IA.
Comment fonctionne la Marketplace
Mise en relation directe et équitable
La plateforme agit comme un canal direct entre les fournisseurs de données et les utilisateurs. Les fournisseurs définissent leurs propres conditions de mise à disposition des données, tandis que les utilisateurs bénéficient d'un accès simplifié à une large gamme de jeux de données qualifiés.
Une API dédiée sera développée pour faciliter la collecte éthique et transparente de données auprès des éditeurs, créateurs, médias et autres titulaires de droits, avec consentement et rémunération garantis.
Traitement et préparation des données
Une fois collectées, les données sont traitées et structurées pour une intégration fluide dans les modèles d'IA. Cela comprend :
La vérification de la qualité
Le nettoyage
La classification
La segmentation
Interface simple et accessible
Les entreprises d'IA et les chercheurs accèdent à des données de haute qualité via une interface intuitive, permettant une innovation continue et l'amélioration des modèles.
Bénéfices pour les parties prenantes
Pour les fournisseurs de données (éditeurs, créateurs, médias)
Monétisation du contenu : les archives, productions actuelles et contenus futurs deviennent des sources de revenus récurrents
Contrôle sur l'utilisation des données : les fournisseurs choisissent ce qui est mis à disposition et protègent leur propriété intellectuelle
Exposition et réputation accrues : la présence sur une plateforme de référence renforce la visibilité et l'influence dans le secteur
Pour les utilisateurs de données (développeurs IA, entreprises, chercheurs)
Accès à des données de haute qualité : un pool riche et diversifié pour des modèles d'IA fiables et adaptatifs
Données actuelles et pertinentes : un accès continu aux contenus récents maintient les modèles à jour
Réduction des coûts de collecte : la centralisation élimine la nécessité de négocier avec plusieurs fournisseurs
FAQ
Pourquoi les pratiques d'utilisation des données d'entraînement soulèvent-elles des préoccupations éthiques ?
Des milliards de pages web sont collectées et utilisées à des fins commerciales sans le consentement ni la compensation des créateurs originaux. Cette pratique, autrefois tolérée pour un usage non commercial, est aujourd'hui contestée juridiquement par des médias, éditeurs et plateformes comme le New York Times.
Combien de sites web bloquent déjà les crawlers IA ?
Selon Originality.AI, environ 20% des 1 000 sites web les plus visités bloquent activement les outils de collecte de données IA. Par ailleurs, 54,3% des éditeurs ont demandé à OpenAI ou Google AI de cesser de crawler leur contenu.
Qu'est-ce qu'une Training Data Marketplace ?
C'est une plateforme qui connecte directement les créateurs de contenu aux entreprises d'IA, permettant des transactions transparentes et rémunérées pour les données utilisées pour entraîner des modèles d'intelligence artificielle.
Qui peut vendre ses données sur cette plateforme ?
Tout titulaire de droits : éditeurs indépendants, créateurs, organisations médiatiques, maisons d'édition, ou toute organisation souhaitant monétiser ses archives de manière éthique et contrôlée.
Conclusion
Construire un marché mondial de données d'entraînement est une étape essentielle vers un développement équilibré et équitable de l'IA, qui respecte les droits individuels et soutient une innovation responsable. Les précédents établis par Reddit et Le Monde montrent que cette voie est viable. AI Partners aide les organisations à comprendre et anticiper les enjeux des droits sur les données, de la propriété intellectuelle et de la gouvernance de l'IA.
.png)